Cluster HA com 3 Masters e HAProxy
Depois de trabalhar bastante com Kubernetes em cloud (EKS, AKS, etc...) e de ter o CKA, quis entender melhor como funciona a instalação manual de um cluster HA. A ideia era simular um cenário próximo de produção no meu homelab.
Arquitetura planejada
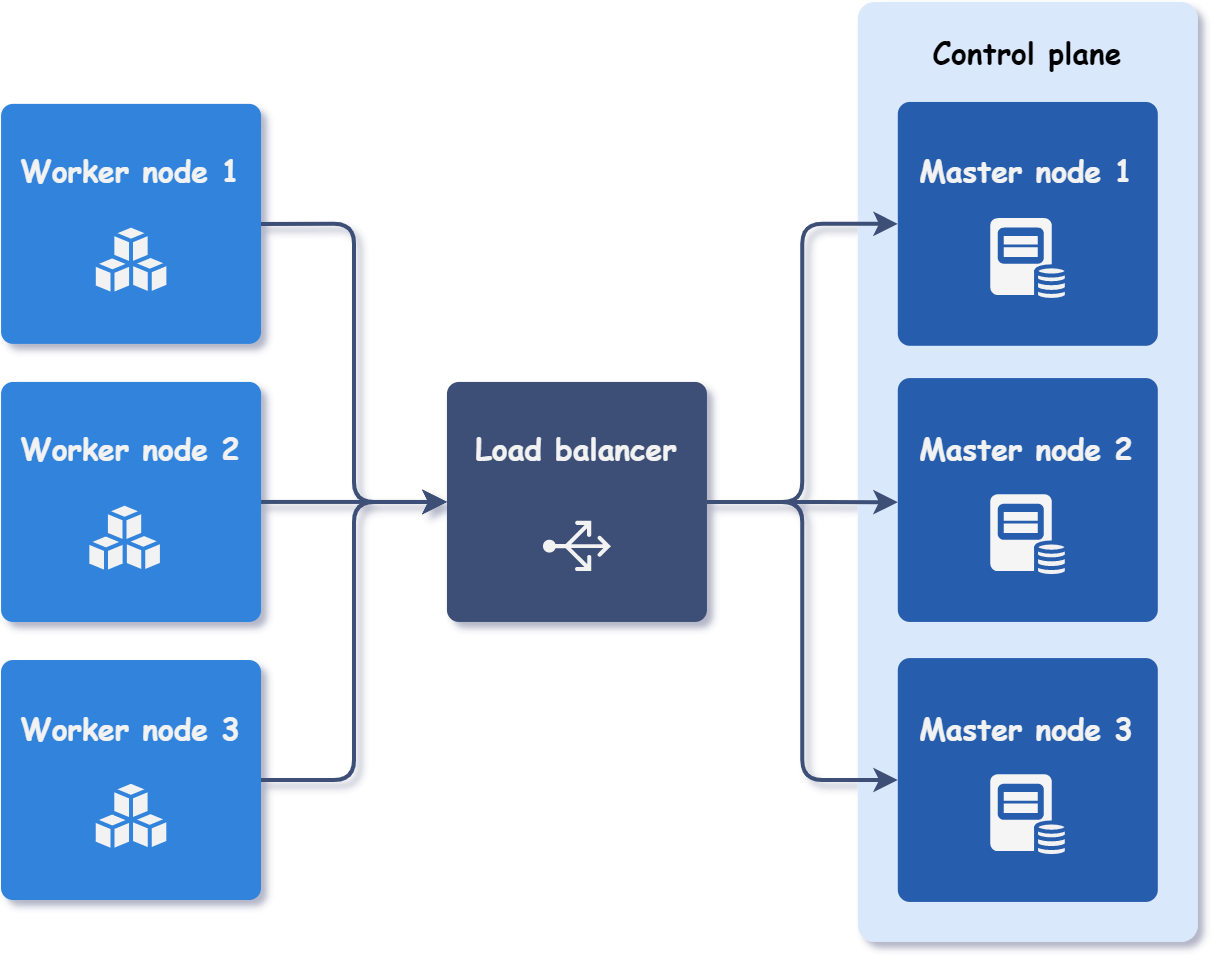 Componentes:
Componentes:
- 3 Masters com etcd stacked (API Server, Controller Manager, Scheduler, etcd)
- 1 VM dedicada para HAProxy (load balancer entre os masters)
- 2 Workers para as cargas de trabalho
- CNI: Calico para networking
Instalação
Passo 1: Preparação geral
Executei em todos os 5 nodes Kubernetes (masters + workers):
# Atualizar sistema
sudo apt update && sudo apt upgrade -y
# Desabilitar swap (Kubernetes não gosta de swap)
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# Carregar módulos de kernel necessários
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# Configurar parâmetros de rede
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
# Instalar containerd
sudo apt install -y containerd
# Configurar containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
# Editar config do containerd para usar systemd cgroup
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl enable containerd
# Adicionar repo do Kubernetes
sudo apt install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.27/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.27/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
# Instalar kubeadm, kubelet, kubectl
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
# Habilitar kubelet
sudo systemctl enable kubelet
Lição aprendida #1: Não pular a configuração do containerd! O SystemdCgroup = true é crítico para o kubelet funcionar corretamente com o systemd.
Passo 2: Configurar HAProxy
Na VM haproxy-lb (192.168.0.8):
sudo apt update
sudo apt install -y haproxy
# Backup da config original
sudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
Configuração do HAProxy (/etc/haproxy/haproxy.cfg):
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
# Frontend para API do Kubernetes
frontend k8s-api
bind *:6443
mode tcp
option tcplog
default_backend k8s-api-backend
# Backend com os 3 masters
backend k8s-api-backend
mode tcp
option tcp-check
balance roundrobin
server master1 192.168.0.7:6443 check fall 3 rise 2
server master2 192.168.0.6:6443 check fall 3 rise 2
server master3 192.168.0.5:6443 check fall 3 rise 2
# Reiniciar HAProxy
sudo systemctl restart haproxy
sudo systemctl enable haproxy
# Verificar se está rodando
sudo systemctl status haproxy
# Verificar se a porta está aberta
sudo ss -tlnp | grep 6443
Lição aprendida #2: HAProxy precisa estar em VM separada ou pelo menos em porta diferente se estiver no mesmo host de um master. Tentei rodar no mesmo servidor do master1 e deu conflito de porta.
Passo 3: O primeiro master
No master1 (192.168.0.7):
# Inicializar cluster apontando para o HAProxy
sudo kubeadm init \
--control-plane-endpoint "192.168.0.8:6443" \
--upload-certs \
--pod-network-cidr=10.5.0.0/16 \
--apiserver-advertise-address=$(hostname -i)
# O comando acima retorna informações importantes:
# 1. Comando para configurar kubectl
# 2. Comando para adicionar masters (com --control-plane)
# 3. Comando para adicionar workers
# GUARDAR ESSES COMANDOS!
Saída esperada (exemplo):
Your Kubernetes control-plane has initialized successfully!
To start using your cluster:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You can now join any number of control-plane nodes by running:
sudo kubeadm join 192.168.0.8:6443 --token abc123.xyz... \
--discovery-token-ca-cert-hash sha256:abc... \
--control-plane --certificate-key 1234567...
Join workers with:
sudo kubeadm join 192.168.0.8:6443 --token abc123.xyz... \
--discovery-token-ca-cert-hash sha256:abc...
Configurar kubectl no master1:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# Verificar
kubectl get nodes
# Deve mostrar master1 como NotReady (normal, falta CNI)
Lição aprendida #3: O --control-plane-endpoint é crítico. Ele define o endereço único que todos os componentes usarão. Sem ele, os workers só conheceriam um master específico.
Passo 4: Instalar CNI (Calico)
Ainda no master1:
# Instalar Calico
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/calico.yaml
# Aguardar pods ficarem prontos (demora uns 2-3 minutos)
watch kubectl get pods -n kube-system
# Verificar node
kubectl get nodes
# Agora master1 deve estar Ready
Passo 5: Adicionar outros masters
No master2 (192.168.0.6) e depois no master3 (192.168.0.5):
# Usar o comando que o kubeadm init te deu
sudo kubeadm join 192.168.0.8:6443 \
--token <token-do-init> \
--discovery-token-ca-cert-hash sha256:<hash-do-init> \
--control-plane \
--certificate-key <certificate-key-do-init>
# Após join completo, configurar kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Passo 6: Adicionar workers
Nos workers (192.168.0.4 e 192.168.0.3):
# Usar comando de join SEM --control-plane
sudo kubeadm join 192.168.0.8:6443 \
--token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
Verificar no master:
kubectl get nodes
# Deve mostrar:
# k8s-master-1 Ready control-plane 10m v1.27.x
# k8s-master-2 Ready control-plane 8m v1.27.x
# k8s-master-3 Ready control-plane 6m v1.27.x
# k8s-worker-1 Ready <none> 3m v1.27.x
# k8s-worker-2 Ready <none> 2m v1.27.x
Portas importantes
| Porta | Protocolo | Componente | Direção |
|---|---|---|---|
| 6443 | TCP | kube-apiserver | Todos → Masters (via LB) |
| 2379-2380 | TCP | etcd | Masters ↔ Masters |
| 10250 | TCP | kubelet API | Masters → Workers |
| 10251 | TCP | kube-scheduler | Local |
| 10252 | TCP | kube-controller-manager | Local |
| 30000-32767 | TCP | NodePort Services | External → Workers |
Troubleshooting: Conectividade
Se o join travar em [check-etcd] Checking that the etcd cluster is healthy, verificar:
- Conectividade de rede entre masters:
# Do master2, testar conectar ao master1
telnet 192.168.0.7 2379 # etcd client
telnet 192.168.0.7 2380 # etcd peer
telnet 192.168.0.7 6443 # API server
- Firewall bloqueando portas:
# Verificar iptables
sudo iptables -L -n
# Se necessário, limpar (só para lab!)
sudo iptables -F
# Em produção, abrir portas específicas:
sudo ufw allow from 192.168.0.0/24 to any port 2379
sudo ufw allow from 192.168.0.0/24 to any port 2380
sudo ufw allow from 192.168.0.0/24 to any port 6443
sudo ufw allow from 192.168.0.0/24 to any port 10250
- Token ou certificate-key expirado:
# Gerar novo token (no master1)
kubeadm token create --print-join-command
# Gerar novo certificate-key
sudo kubeadm init phase upload-certs --upload-certs
# Retorna: certificate-key: abc123...
Lição aprendida #4: Os masters precisam conversar diretamente entre si nas portas do etcd (2379, 2380). O HAProxy só distribui tráfego da API (6443), mas a replicação do etcd é peer-to-peer.
Troubleshooting: cluster etcd
Em qualquer master:
# Listar membros do etcd
sudo ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list
# Saída esperada: 3 members (um por master)
# Verificar saúde
sudo ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
endpoint health
Com 3 members, o etcd tolera 1 falha. O quorum é (n/2)+1 = 2.
Testes de HA
Teste 1: Failover do HAProxy
# Desligar master1
ssh 192.168.0.7
sudo shutdown -h now
# Do laptop/bastion, continuar usando kubectl
kubectl get nodes
# Deve continuar funcionando! HAProxy roteia para master2 ou master3
Teste 2: Falha de um master
# Desligar master2
ssh 192.168.0.6
sudo shutdown -h now
# Cluster continua funcional (quorum: 2 de 3 masters ainda ativos)
kubectl get pods -A
Teste 3: Deploy de aplicação
# Criar deployment nos workers
kubectl create deployment nginx --image=nginx --replicas=3
# Expor
kubectl expose deployment nginx --port=80 --type=NodePort
# Verificar distribuição
kubectl get pods -o wide
# Pods devem estar nos workers, não nos masters
Comandos úteis para troubleshooting
# Ver logs do kubelet
sudo journalctl -u kubelet -f
# Ver logs de um pod do sistema
kubectl logs -n kube-system <pod-name>
# Verificar certificados
sudo kubeadm certs check-expiration
# Renew certificados
sudo kubeadm certs renew all
# Ver config do cluster
kubectl -n kube-system get cm kubeadm-config -o yaml
# Debugging de rede
kubectl run tmp-shell --rm -i --tty --image nicolaka/netshoot
# Ver eventos do cluster
kubectl get events -A --sort-by='.lastTimestamp'